





Never would have imagined that the laws of physics would be so important in a world where virtualization is the new normal.
Data Locality is Important
Data Locality, refers to the ability to move the computation close to the data. This is important because when performance is key, IO quickly becomes our number one bottleneck. Data access times vary from milliseconds to seconds because of many factors like hardware specifications and network capabilities.
Let’s explore Data Locality through the following Scenario. I have eight files containing data about multiple trucks, and I need to Identify trips. A trip consists of many segments, including short stops. So if the driver stops for coffee and starts again, this is still considered the same trip. The strategy depicted below is to read each file and to group data points by truck. This can be referred to as mapping the data. Then we can compute the trips for each group in parallel over multiple threads. This can be referred to as reducing the data. And finally, we merge the results in a single CSV file so that we can easily import it to other systems like SQL Server and Power BI.
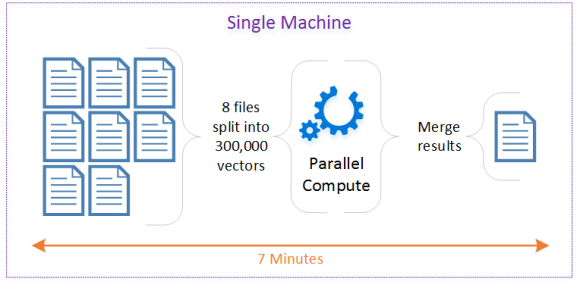
The single machine configuration results were promising. So I decided to break it apart and distribute the process across many task Virtual Machines (TVM). Azure Batch is the perfect service to schedule jobs. Continue Reading…








 This week I was face with an odd scenario. I needed to track URIs that are store in
This week I was face with an odd scenario. I needed to track URIs that are store in 


